
เกมนั้นเป็นผลงานทางศิลปะที่เกิดขึ้นจากความฉลาดของมนุษย์ เพราะฉะนั้นมันไม่ได้มีประโยชน์แค่เล่นสนุกอย่างเดียวแน่นอน ล่าสุดเมื่อซัมเมอร์ที่ผ่านมา นักวิจัยจาก Pittsburgh University อเมริกา ได้ใช้เกมในการสอนให้ Ai นั้นเรียนรู้จากความผิดพลาด
ผู้ช่วยศาตราจารย์ ด็อกเตอร์ Daniel Jiang จากคณะวิศวกรรมอุตสาหการ มหาวิทยาลัยพิตต์สเบิร์ก ได้อธิบายว่า การศึกษานี้จะเป็นการสร้างอัลกอริทึมที่สามารถเรียนรู้จากความผิดพลาดได้ โดยการใช้เกม MOBA เพื่อทดสอบประสิทธิภาพของอัลกอริทึมนั้น โดยเกมที่ใช้ทดสอบคือ DotA 2, Heroes of the Storm และ League of Legends
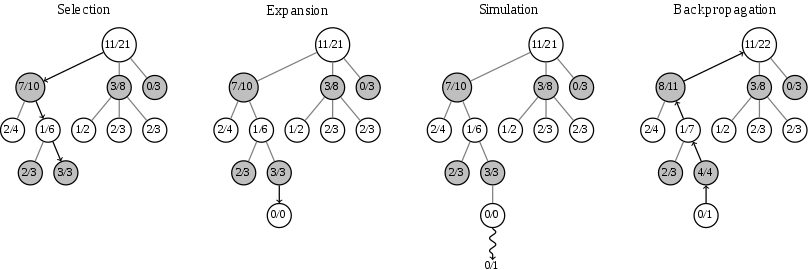
ด็อกเตอร์ Jiang ได้สร้างอัลกอริทึมที่สามารถรวบรวมข้อมูล 41 อย่างภายในเกม โดยมันจะคิดและคำนวนหาการตอบโต้ที่เหมาะสมกับแต่ละเหตุการณ์ได้ถึง 22 แบบ (เช่น โจมตี เคลื่อนไหว ใช้สกิล และการเดินแบบต่าง ๆ) ผลการทดลองสรุปได้ว่า Ai ที่ใช้กระบวนการที่เรียกว่า Monte Carlo tree search strategy ซึ่งเป็นขั้นตอนการตัดสินใจเลือกที่เป็นระบบนั้น จะมีโอกาสชนะที่สูงกว่า Ai ปรกติที่ไม่ได้เรียนรู้วิธีนี้
ซึ่ง Monte Carlo tree search เป็นการบวนการตัดสินใจอย่างเป็นระบบ โดยถูกใช้อย่างแพร่ในเกมต่างกลยุทธ์ต่าง ๆ เช่น โกะ โซกิ และ หมากรุก เป็นต้น นอกจากนี้ยังถูกใช้ในเกมชื่อดังอย่าง Total War: Rome II เพื่อให้ Ai ในเกมนั้นมีความฉลาดและความหลากหลายในการโจมตีมากขึ้น โดย Ai จะเรียนรู้การกระทำที่จะช่วยให้ชนะเกมและจดจำมันไปใช้ในเกมต่อ ๆ ทำให้มันจะฉลาดขึ้นทุกครั้งที่เกมจบลงโดยมันจะไม่ทำผิดพลาดแบบเดิม ๆ อีกต่อไป คล้ายกับที่มนุษย์สามารถที่จะเรียนรู้จากความผิดพลาดได้นั้นเอง
Source: v3











